Fraunhofer IIS - The focus of this tech blog is on SoC FPGAs. These are system-on-a-chip solutions that integrate programmable hardware structures of an FPGA alongside processor cores that are often based on ARM technology. Typically, part of these FPGA structures can be used to implement hardware accelerators. These reduce the load on the software running on the integrated processor and lead to faster results. The question arises as to whether energy can be saved by using these hardware structures?
The term hardware virtualization is not yet familiar. This type of virtualization presupposes that hardware can be changed during operation. FPGAs that can be partially reconfigured during operation support this process well. With this type of virtualization, a software container contains programming information for various hardware structures in addition to software components. These are loaded into selected areas of the FPGA as required. It should be noted that this is not a pure hardware solution. A co-processor requires a proxy in software that supplies the hardware with data and retrieves the result of the calculation.
An application interface to the FPGA is required for HW virtualization. This API can be used by the processor to program sub-areas within the FPGA or to transfer and read data to the hardware structure. Furthermore, an interface between the software in the container and the FPGA API is used.
The actual applications work in the virtualized container environment of the processor. When a container is started, a management software retrieves information as to whether sufficient space is available in one of the partial areas in the FPGA for the associated hardware implementation. If this is the case, the HW design is loaded into the FPGA. If there are not enough resources available, a software component with the same functionality stored in the container is started instead.
In order to evaluate the results of HW virtualization, a test design was created in the form of a neural network as a typical representative of a co-processor. Various implementations were then tested for their performance and energy efficiency. The results are shown in the diagram below.
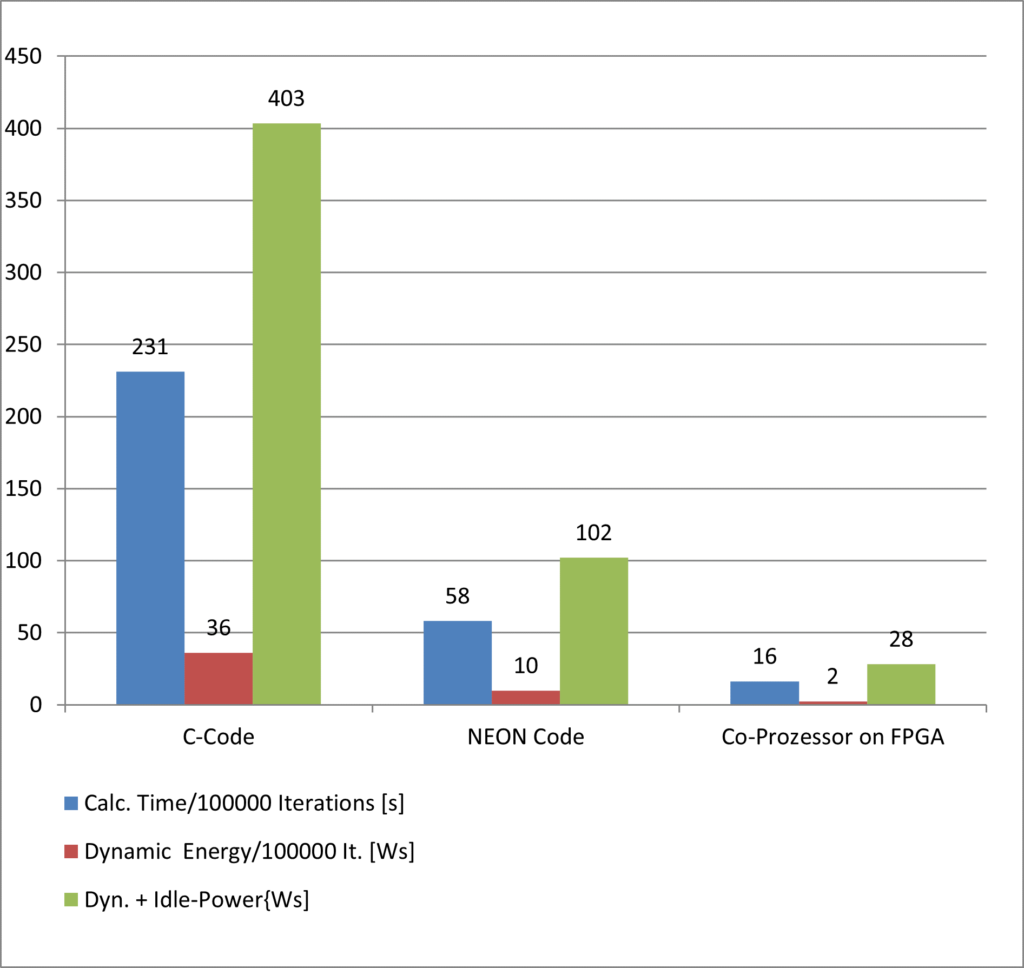
The first two solutions in the diagram show two pure software implementations of the neural network: a non-optimized version written in the C programming language and a second version that uses optimized NEON code for ARM processors. The blue bars represent the execution speed, the red bars the energy consumption for the execution of the neural network over 10,000 complete runs, and the green bars the total energy consumption including the static energy consumption for each solution. Even the use of optimized C code leads to a significantly more energy-efficient and faster implementation. In comparison, the use of a hardware accelerator enables additional dynamic energy savings by a factor of 5.